Rolling Hash and Content-Based Chunking
PostedWhen dealing with large sets/streams of data, it might be useful to split them into small chunks of data, for various reasons. For example to track dupes and use the resulting data deduplication to reduce needed bandwidth and/or storage.
Of course you can just decide of a given (fixed) size, and cut every time that many bytes went by, but that's not ideal. The way I had implemented this was based on a rolling hash based on the Rabin fingerprint to perform such content-based chunking.
It's a typical way of achieving such a thing, giving better results for deduplication that a basic fixed-length chunking and being pretty fast, due to the properties of rolling hashes.
However, as I've been doing lately, I wondered whether other implementations couldn't give me better/faster results, so I went on and decided to do some benchmarks again.
Testing...
As I mentioned I knew of rabin-based chunking, and I did find another (very similar) implementation based on rabin fingerprint. However the interesting bit is that it came in three flavors no less!
Note that all rabin variants use the same precomputed tables (for a window size of 32 bytes) which I won't include here but that are obviously available along with the rest of the source code.
Rabin fingerprint
This one and the other two variants came from Min Fu.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
c#include "rabin-tables.h"
#define BREAKMARK_VALUE 0x78
size_t
nextsplit(size_t min, size_t avg, const void *data, size_t dlen)
{
if (dlen <= min) return dlen;
u64 mask = (1 << (msb64(avg) - 1)) - 1;
u64 fp = 0;
int i = min, wpos = -1;
const u8 *sce = data;
u8 window[RABIN_WINDOW_SIZE] = { 0 };
while (i < dlen) {
u8 om;
u64 x;
if (++wpos >= sizeof(window))
wpos = 0;
om = window[wpos];
window[wpos] = sce[i - 1];
fp ^= rabin_tables.U[om];
x = fp >> 55;
fp <<= 8;
fp |= sce[i - 1];
fp ^= rabin_tables.T[x];
if (i >= min && (fp & mask) == BREAKMARK_VALUE)
break;
++i;
}
return i;
}
Your usual rabin-based rolling hash computation and check against a mask to
decide whether or not to make a split at the current position. Note that it did
use a special BREAKMARK_VALUE value instead of just checking for all lower
bits beings set (or not).
Double-mask variant
The first variant is pretty much the same, but makes use of two masks in order to decide whether or not to make a split.
The idea being that if we're so far under the average/targeted block size, the first mask for a larger average/target size is being used, but once we're past that point and our chunk start getting past the average size, the second mask for a smaller average chunk size gets used.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
c#include "rabin-tables.h"
#define BREAKMARK_VALUE 0x78
size_t
nextsplit(size_t min, size_t avg, const void *data, size_t dlen)
{
if (dlen <= min) return dlen;
u64 sml_mask = (1 << (msb64(avg * 2) - 1)) - 1;
u64 lrg_mask = (1 << (msb64(avg / 2) - 1)) - 1;
u64 fp = 0;
int i = min, wpos = -1;
const u8 *sce = data;
u8 window[RABIN_WINDOW_SIZE] = { 0 };
while (i < dlen) {
u8 om;
u64 x;
if (++wpos >= sizeof(window))
wpos = 0;
om = window[wpos];
window[wpos] = sce[i - 1];
fp ^= rabin_tables.U[om];
x = fp >> 55;
fp <<= 8;
fp |= sce[i - 1];
fp ^= rabin_tables.T[x];
if (i >= min) {
if (i < avg) {
if ((fp & sml_mask) == BREAKMARK_VALUE)
break;
} else if ((fp & lrg_mask) == BREAKMARK_VALUE)
break;
}
++i;
}
return i;
}
The Two Thresholds, Two Divisors Algorithm (TTTD) variant
The other variant was using a similar technique, but slightly differently: in addition to the "regular" mask is another one, to provide a "backup breakpoint" should we fail to find one with the original mask.
So the chunking is done relying on the original mask as before, but we also always check for a possible backup split ahead of time. That way, comes the end of the stream (or maximum bock size reached), instead of having a maximum-length chunk we can fall back on the last "backup breakpoint" found (if any).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
c#include "rabin-tables.h"
#define BREAKMARK_VALUE 0x78
size_t
nextsplit(size_t min, size_t avg, const void *data, size_t dlen)
{
if (dlen <= min) return dlen;
u64 mask = (1 << (msb64(avg ) - 1)) - 1;
u64 lrg_mask = (1 << (msb64(avg / 2) - 1)) - 1;
u64 fp = 0;
int i = min, wpos = -1;
int m = 0;
const u8 *sce = data;
u8 window[RABIN_WINDOW_SIZE] = { 0 };
while (i < dlen) {
u8 om;
u64 x;
if (++wpos >= sizeof(window))
wpos = 0;
om = window[wpos];
window[wpos] = sce[i - 1];
fp ^= rabin_tables.U[om];
x = fp >> 55;
fp <<= 8;
fp |= sce[i - 1];
fp ^= rabin_tables.T[x];
if (i >= min) {
if ((fp & lrg_mask) == BREAKMARK_VALUE) {
if ((fp & mask) == BREAKMARK_VALUE)
return i;
m = i;
}
}
++i;
}
if (m)
return m;
return i;
}
A mix of all rabin-based variants
In the end I ended up tweaking my original implementation, to use the double-mask variant for average size under 128 KiB, and from then onwards switch to the TTTD variant. Why, you ask? Because a few tests seemed to indicate that would get better deduplication that way. Maybe. Sometimes. Since of course, different data will lead to different results, and that might not always end up being the best possible rabin-based variant.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
c#include "rabin-tables.h"
size_t
nextsplit(size_t min, size_t avg, const void *data, size_t dlen)
{
if (dlen <= min) return dlen;
u8 window[RABIN_WINDOW_SIZE] = { 0 };
const u8 *b = data;
size_t wpos = 0, pos = min, last = 0;
u64 fp = 0;
u64 mask, lrg_mask;
int tttd = avg >= (128 << 10);
if (tttd)
mask = (1 << (msb64(avg ) - 1)) - 1;
else
mask = (1 << (msb64(avg * 2) - 1)) - 1;
lrg_mask = (1 << (msb64(avg / 2) - 1)) - 1;
#define TTTD_BREAK 0x78
#define APPEND8(p,m) (((p) << 8) | m) ^ rabin_tables.T[(p) >> 55]
for (;;) {
u8 old = window[wpos];
window[wpos] = b[pos];
fp = APPEND8(fp ^ rabin_tables.U[old], window[wpos]);
if (++wpos == sizeof(window)) wpos = 0;
if (pos == dlen) {
if (last) return last;
return pos;
}
if (pos >= min) {
if (tttd) {
if ((fp & lrg_mask) == TTTD_BREAK) {
if ((fp & mask) == TTTD_BREAK)
return pos;
last = pos;
}
} else if (pos < avg) {
if ((fp & mask) == mask)
return pos;
} else if ((fp & lrg_mask) == lrg_mask) {
return pos;
}
}
++pos;
}
}
Those tests & branches will have a speed effect, but hopefully not too bad. Also this original implementation was slightly faster than Min Fu's, so it might help a bit mitigate things.
Hashchop, rsync-inspired
Another chunking method I found came from Scott Vokes, and is said to be inspired/using the same basis as can be found in rsync, which itself is based on Adler's CRC32 checksum.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
csize_t
nextsplit(size_t min, size_t avg, const void *data, size_t dlen)
{
if (dlen <= min) return dlen;
u32 mask = (1 << (msb64(avg) - 1)) - 1;
const u8 *buf = data;
u32 a = 1, b = 0;
size_t offset;
for (u32 i = 0; i < min; ++i) {
a += buf[i];
b += (min - i + 1) * buf[i];
}
a &= mask;
b &= mask;
for (offset = min; offset < dlen; ++offset) {
u32 k = offset - min;
u32 l = offset;
u8 nk = buf[k];
u8 nl = buf[l];
u32 na = (a - nk + nl);
u32 nb = (b - (l - k + 1) * nk + na);
u32 checksum = (na + (nb << 16)) & mask;
if (checksum == 0) break;
a = na;
b = nb;
}
return offset;
}
Cool thing is, it doesn't need pre-computed tables. What you see above is all it needs.
buzhash
Going back to the use of pre-computed tables, comes an implementation of another rolling hash called buzhash. This is based on code from BorgBackup.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
csize_t
nextsplit(size_t min, size_t avg, const void *data, size_t dlen)
{
u32 T[] = BUZTABLE;
u32 mask = (1 << (msb64(avg) - 1)) - 1;
#define WINDOW_SIZE 2047
#define BARREL_SHIFT(v, shift) ( ((v) << (shift)) | ((v) >> ((32 - (shift)) & 0x1F)) )
const u8 *d = data;
u32 i, sum, imod;
if (dlen <= min + WINDOW_SIZE) return dlen;
sum = 0;
for (i = WINDOW_SIZE - 1; i > 0; --i) {
imod = i & 0x1F;
sum ^= BARREL_SHIFT(T[*d], imod);
++d;
}
sum ^= T[*d];
d = data;
for (i = WINDOW_SIZE; i < dlen - WINDOW_SIZE; ++i) {
sum = BARREL_SHIFT(sum, 1) ^ BARREL_SHIFT(T[*d], 0x1F) ^ T[d[WINDOW_SIZE]];
if ((sum & mask) == 0) break;
++d;
}
if (i >= dlen - WINDOW_SIZE)
i = dlen;
return i;
}
Note that I've not included the previously mentioned table here, but as before the full source code is available.
Also the main change compared to BorgBackup's original implementation is in the window size, here reduced from 4095 to 2047. This might have a little negative effect of speed, but (again, based on a few tests a I ran) seems to get slightly better (deduplication) results, so I went for it.
Asymmetric Extremum Content Defined Chunking
Finally, here's one I discovered while researching this. A completely different content-based chunking algorithm by Yucheng Zhang, that doesn't need pre-computed table nor does it uses a rolling hash for that matter. It's all about giving every block of data a position and a value and comparing said values. I'm not gonna try and describe it more than that, but feel free to read the associated paper if you're interested.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
c#if __BYTE_ORDER == __BIG_ENDIAN
# define GETLE64(u) (u)
#else
# define GETLE64(u) __builtin_bswap64(u)
#endif
static inline
int cmp(const u8 *x, const u8 *y)
{
int ret;
u64 a = GETLE64(* ((u64 *) x));
u64 b = GETLE64(* ((u64 *) y));
if (a > b)
ret = 1;
else
ret = -1;
return ret;
}
size_t
nextsplit(size_t min, size_t avg, const void *data, size_t dlen)
{
if (dlen <= min) return dlen;
double e = 2.718281828;
int window_size = avg / (e - 1);
/* cur points to the current position
* max points to the position of max value
* end points to the end of buffer
*/
const u8 *cur = (const u8 *) data + 1;
const u8 *max = (const u8 *) data;
const u8 *end = (const u8 *) data + dlen - sizeof(u64);
if (dlen <= window_size + sizeof(u64))
return dlen;
for ( ; cur <= end; ++cur) {
if (cmp(cur, max) < 0) {
max = cur;
continue;
}
if (cur == max + window_size)
return cur - (const u8 *) data;
}
return dlen;
}
AE-32
Just because I was curious, I also tried a variant of the previous algorithm but using u32 instead of u64 as blocks of data with a value. Notably to see how it would perform on a 32bit system.
One.. Two.. Test!
So for the tests, I originally started with pretty "theoretical" stuff and used
some random data - as in read from /dev/urandom - but eventually I figured
that wouldn't necessarily give worthy results, so I updated the testing bit to
read the given file and split it into chunks, or if given a directory then
recursively chunk every file in there.
Now of course nothing is changed/saved, files are only read, but at least it gives results based on some "real-life" data.
The code
I won't include the code here, in part because I'm lazy ;p and in part because
it feels unnecessary. That is, the main bit just calls nextsplit() from the
start of the data read up to maxsize, then from the returned offset up to
maxsize again, and so on until the entire file/data has been processed.
Other than that it's all reading the file, or directory in which case... you know the drill. Plus, the full source code can be browsed if needed.
Speed
For speed comparisons I've used kernel/trace/trace.c from linux-5.10.167 -
because it was a somewhat large file so there would be some chunking happening.
Specifically the file is 241,280 bytes and I ran tests through 4200 iterations. As often before I ran them on 64bit and 32bit systems. And the winners are...
64bit

Yes, AE is a wonder of speed, and in fact the 32bit variant manages to be even faster. We're indeed talking more than 1.2 GiB/s ! At this rate it's you who needs to make sure you can feed it data fast enough :)
Other than that buzhash is darn fast as well at over 800 MiB/s, and hashchop not far behind it.
The rabin-based implementations don't perform that well - not to say 500 MiB/s is slow - and amongst them rabin-mix performs better. It might be worthy to note than this test was ran with 8 KiB average size, so rabin-mix is then using the double-mask variant, which is indeed the fastest one of the bunch.
However I did run tests with different average sizes (on random data) and though there are variations in speed, the repartition remain the same.
32bit
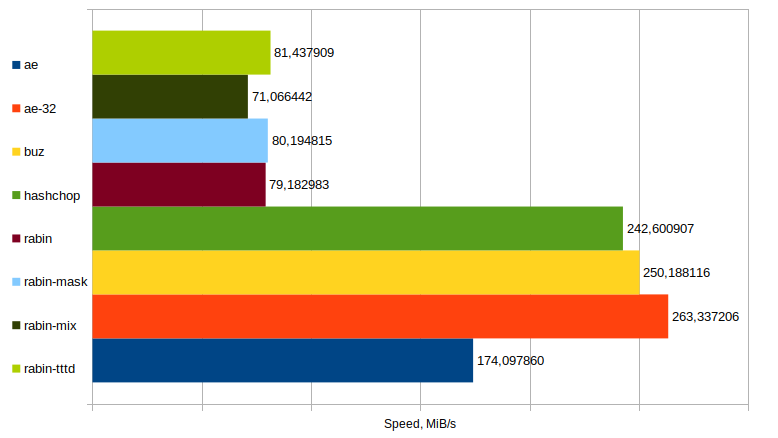
This time around, as expected, the 32bit variant of AE continues to perform marvellously whereas its 64bit counterpart takes a hit.
Such a hit that both buzhash & hashchop outperforms it easily, being closer to ae-32 than ae.
Once again rabin-based chunking are slower, and this time around rabin-mix gets to be the worst of them all. Oh well.
Raw results
64bit
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
outputtest-ae:
29 blocks; min=4878, avg=8320, max=16572
took 0.789294209 seconds, 1224.423863 MiB/s
test-ae-32:
11 blocks; min=9988, avg=21934, max=56709
took 0.704321791 seconds, 1372.143637 MiB/s
test-buz:
18 blocks; min=2111, avg=13404, max=33029
took 1.176212677 seconds, 821.646189 MiB/s
test-hashchop:
18 blocks; min=4117, avg=13404, max=34669
took 1.235816999 seconds, 782.017617 MiB/s
test-rabin:
21 blocks; min=5194, avg=11489, max=28036
took 1.905959775 seconds, 507.057220 MiB/s
test-rabin-mask:
21 blocks; min=4096, avg=11489, max=28171
took 1.843783343 seconds, 524.156305 MiB/s
test-rabin-mix:
22 blocks; min=4363, avg=10967, max=22992
took 1.782239865 seconds, 542.256227 MiB/s
test-rabin-tttd:
21 blocks; min=5194, avg=11489, max=28036
took 1.925576349 seconds, 501.891636 MiB/s
32bit
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
outputtest-ae:
29 blocks; min=4878, avg=8320, max=16572
took 5.551077201 seconds, 174.097860 MiB/s
test-ae-32:
11 blocks; min=9988, avg=21934, max=56709
took 3.669935897 seconds, 263.337206 MiB/s
test-buz:
18 blocks; min=2111, avg=13404, max=33029
took 3.862816026 seconds, 250.188116 MiB/s
test-hashchop:
18 blocks; min=4117, avg=13404, max=34669
took 3.983623463 seconds, 242.600907 MiB/s
test-rabin:
21 blocks; min=5194, avg=11489, max=28036
took 12.205029701 seconds, 79.182983 MiB/s
test-rabin-mask:
21 blocks; min=4096, avg=11489, max=28171
took 12.051036799 seconds, 80.194815 MiB/s
test-rabin-mix:
22 blocks; min=4363, avg=10967, max=22992
took 13.598973497 seconds, 71.066442 MiB/s
test-rabin-tttd:
21 blocks; min=5194, avg=11489, max=28036
took 11.867085927 seconds, 81.437909 MiB/s
Data deduplication
In order to test data deduplication a little more work was needed (and I'll let
curious people go read the source code for details) but what was done was run
the tests on the entire source code from linux-5.10.161 and then on the
linux-linux-5.15.93 tree.
Firstly the "internal deduplication" from within the 5.10 tree was computed, and then the deduplication from the 5.10 to the 5.15 trees was computed. Those computations consisted of listing chunks (identified by their hash, BLAKE3 in this case) and looking for dupes (and how many times they were found).
Tests were done with different average/targeted block size : 8, 16, 32, 64, 128, 256, 512 and 1024 KiB. Note that they were only done on 64bit system this time, since actual chunking results don't change from one arch to the other.
Deduplication within linux 5.10.167

Well, a graph don't lie : buzhash is a clear winner.
The differences are left to see who can get closer to it. With larger blocks there's not much differences actually, but then again we're talking text files so I'm not sure there are that many chances to
As block size get smaller and smaller, everyone gets to perform better, and buz remain clearly ahead of every others. The rabin-based chunking get better and better, and amongst them rabin-mix manages to take the lead, AE gets left behind more & more.
Deduplication from linux 5.10.167 to linux 5.15.93
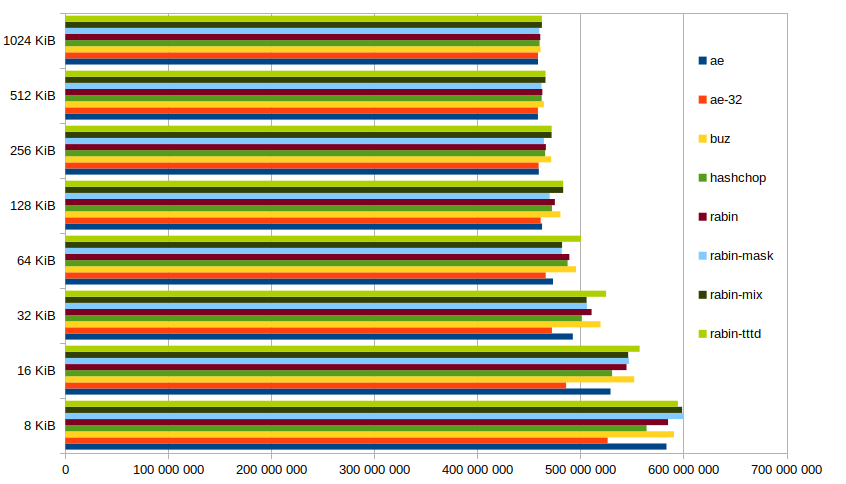
This time around it isn't as obvious. About everyone seems to perform in the same range, except maybe for ae-32 which underperforms. (But hey, at least it remains faster than the competition.)
At 8 KiB the rabin-based chunking perform better, almost 10 MiB better than buz. Then until 128 KiB only rabin-tttd managed to do better, at which point rabin-mix joins in (since it then uses the TTTD variant),
So possibly using rabin-based chunking might get you better deduplication, but at a cost : buz might not perform as well, but it is almost twice as fast.
Raw results
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
405
406
407
408
409
410
411
412
413
414
415
416
417
418
419
420
421
422
423
424
425
426
427
428
429
430
431
432
433
434
435
436
437
438
439
440
441
442
443
444
445
446
447
448
449
450
451
452
453
454
455
456
457
458
459
460
461
462
463
464
465
466
467
468
469
470
471
472
473
474
475
476
477
478
479
480
481
482
483
484
485
486
487
488
489
490
491
492
493
494
495
496
497
498
499
500
501
502
503
504
505
506
507
508
509
510
511
512
513
514
515
516
517
518
519
520
521
522
523
524
525
526
527
528
529
530
531
532
533
534
535
536
537
538
539
540
541
542
543
544
545
546
547
548
549
550
551
552
553
554
555
556
557
558
559
560
561
562
563
564
565
566
567
568
569
570
571
572
573
574
575
576
577
578
579
580
581
582
583
584
585
586
587
588
589
590
591
592
593
594
595
596
597
598
599
output8 KiB
* ae:
/tmp/linux-5.10.167
136152 blocks; min=5, avg=7284, max=1048576
took 2.118390380 seconds, 446.476544 MiB/s
dedup: 39526633
/tmp/linux-5.15.93
144053 blocks; min=5, avg=7705, max=1048576
took 2.332347460 seconds, 453.841065 MiB/s
dedup: 583480200
* ae-32:
/tmp/linux-5.10.167
103710 blocks; min=4, avg=9562, max=1048576
took 1.933890963 seconds, 489.071842 MiB/s
dedup: 39123770
/tmp/linux-5.15.93
110022 blocks; min=4, avg=10088, max=1048576
took 2.138209049 seconds, 495.047505 MiB/s
dedup: 526350290
* buz:
/tmp/linux-5.10.167
149936 blocks; min=5, avg=6614, max=101336
took 2.385848928 seconds, 396.425609 MiB/s
dedup: 58672897
/tmp/linux-5.15.93
163715 blocks; min=5, avg=6779, max=101336
took 2.701707035 seconds, 391.794907 MiB/s
dedup: 590794479
* hashchop:
/tmp/linux-5.10.167
129088 blocks; min=1, avg=7682, max=395977
took 2.495007707 seconds, 379.081641 MiB/s
dedup: 50435228
/tmp/linux-5.15.93
139601 blocks; min=1, avg=7950, max=395977
took 2.762983977 seconds, 383.105753 MiB/s
dedup: 564138812
* rabin:
/tmp/linux-5.10.167
128893 blocks; min=2, avg=7694, max=341302
took 3.107453726 seconds, 304.368688 MiB/s
dedup: 49583183
/tmp/linux-5.15.93
137848 blocks; min=2, avg=8051, max=386303
took 3.459460509 seconds, 305.976915 MiB/s
dedup: 584979896
* rabin-mask:
/tmp/linux-5.10.167
135872 blocks; min=1, avg=7299, max=176878
took 3.010917071 seconds, 314.127421 MiB/s
dedup: 55833888
/tmp/linux-5.15.93
146197 blocks; min=1, avg=7592, max=331249
took 3.398986417 seconds, 311.420796 MiB/s
dedup: 600292060
* rabin-mix:
/tmp/linux-5.10.167
135779 blocks; min=1, avg=7304, max=235204
took 3.041172267 seconds, 311.002315 MiB/s
dedup: 55850924
/tmp/linux-5.15.93
146725 blocks; min=1, avg=7564, max=235204
took 3.372967579 seconds, 313.823074 MiB/s
dedup: 598617424
* rabin-tttd:
/tmp/linux-5.10.167
138443 blocks; min=1, avg=7163, max=341302
took 3.195774711 seconds, 295.956912 MiB/s
dedup: 49795928
/tmp/linux-5.15.93
147858 blocks; min=1, avg=7506, max=386303
took 3.582147805 seconds, 295.497314 MiB/s
dedup: 594539857
16 KiB
* ae:
/tmp/linux-5.10.167
100566 blocks; min=5, avg=9861, max=1048576
took 1.953588447 seconds, 484.140668 MiB/s
dedup: 37666040
/tmp/linux-5.15.93
106380 blocks; min=5, avg=10433, max=1048576
took 2.105947290 seconds, 502.631315 MiB/s
dedup: 529184080
* ae-32:
/tmp/linux-5.10.167
83686 blocks; min=5, avg=11850, max=1048576
took 1.827103584 seconds, 517.656264 MiB/s
dedup: 37535781
/tmp/linux-5.15.93
88749 blocks; min=5, avg=12506, max=1048576
took 1.993320832 seconds, 531.030950 MiB/s
dedup: 486087731
* buz:
/tmp/linux-5.10.167
116476 blocks; min=5, avg=8514, max=152821
took 2.286089081 seconds, 413.724742 MiB/s
dedup: 51472976
/tmp/linux-5.15.93
125657 blocks; min=5, avg=8833, max=152821
took 2.559618247 seconds, 413.544112 MiB/s
dedup: 552170341
* hashchop:
/tmp/linux-5.10.167
104512 blocks; min=1, avg=9489, max=549818
took 2.485783256 seconds, 380.488368 MiB/s
dedup: 42990203
/tmp/linux-5.15.93
111843 blocks; min=1, avg=9924, max=925955
took 2.725321961 seconds, 388.400002 MiB/s
dedup: 530649381
* rabin:
/tmp/linux-5.10.167
105678 blocks; min=2, avg=9384, max=453549
took 3.281004032 seconds, 288.268958 MiB/s
dedup: 41214044
/tmp/linux-5.15.93
112017 blocks; min=2, avg=9908, max=453549
took 3.702161739 seconds, 285.918101 MiB/s
dedup: 544703532
* rabin-mask:
/tmp/linux-5.10.167
103718 blocks; min=2, avg=9562, max=348161
took 3.282621848 seconds, 288.126887 MiB/s
dedup: 45572988
/tmp/linux-5.15.93
110607 blocks; min=2, avg=10034, max=386303
took 3.743363602 seconds, 282.771103 MiB/s
dedup: 547010580
* rabin-mix:
/tmp/linux-5.10.167
104007 blocks; min=2, avg=9535, max=449144
took 3.250674206 seconds, 290.958600 MiB/s
dedup: 46980003
/tmp/linux-5.15.93
111333 blocks; min=2, avg=9969, max=449144
took 3.734955014 seconds, 283.407712 MiB/s
dedup: 546270792
* rabin-tttd:
/tmp/linux-5.10.167
114151 blocks; min=1, avg=8688, max=453549
took 3.355874339 seconds, 281.837614 MiB/s
dedup: 41709543
/tmp/linux-5.15.93
120943 blocks; min=1, avg=9177, max=453549
took 3.825554622 seconds, 276.695842 MiB/s
dedup: 557436866
32 KiB
* ae:
/tmp/linux-5.10.167
84541 blocks; min=5, avg=11731, max=1048576
took 1.733248373 seconds, 545.687294 MiB/s
dedup: 35447533
/tmp/linux-5.15.93
89224 blocks; min=5, avg=12439, max=1048576
took 1.928703545 seconds, 548.822062 MiB/s
dedup: 492575598
* ae-32:
/tmp/linux-5.10.167
78085 blocks; min=5, avg=12700, max=1048576
took 1.678589308 seconds, 563.456237 MiB/s
dedup: 35374773
/tmp/linux-5.15.93
82420 blocks; min=5, avg=13466, max=1048576
took 1.848969303 seconds, 572.489253 MiB/s
dedup: 472285905
* buz:
/tmp/linux-5.10.167
96809 blocks; min=5, avg=10244, max=253565
took 2.269504741 seconds, 416.748023 MiB/s
dedup: 45222126
/tmp/linux-5.15.93
103259 blocks; min=5, avg=10749, max=282524
took 2.526177317 seconds, 419.018510 MiB/s
dedup: 519452069
* hashchop:
/tmp/linux-5.10.167
89498 blocks; min=1, avg=11081, max=1048576
took 2.473902855 seconds, 382.315584 MiB/s
dedup: 36328486
/tmp/linux-5.15.93
94907 blocks; min=1, avg=11694, max=1048576
took 2.742364701 seconds, 385.986246 MiB/s
dedup: 501309008
* rabin:
/tmp/linux-5.10.167
91678 blocks; min=2, avg=10817, max=1048576
took 3.451163297 seconds, 274.055886 MiB/s
dedup: 35989433
/tmp/linux-5.15.93
96740 blocks; min=2, avg=11473, max=1048576
took 3.830253519 seconds, 276.356395 MiB/s
dedup: 510794144
* rabin-mask:
/tmp/linux-5.10.167
88094 blocks; min=2, avg=11257, max=453549
took 3.500204550 seconds, 270.216098 MiB/s
dedup: 37900676
/tmp/linux-5.15.93
93121 blocks; min=2, avg=11919, max=453549
took 3.907115215 seconds, 270.919847 MiB/s
dedup: 506259190
* rabin-mix:
/tmp/linux-5.10.167
87677 blocks; min=3, avg=11311, max=752113
took 3.433639624 seconds, 275.454538 MiB/s
dedup: 38086999
/tmp/linux-5.15.93
92894 blocks; min=3, avg=11948, max=1048576
took 3.928038488 seconds, 269.476753 MiB/s
dedup: 505938329
* rabin-tttd:
/tmp/linux-5.10.167
98147 blocks; min=2, avg=10104, max=976853
took 3.567730146 seconds, 265.101781 MiB/s
dedup: 36471999
/tmp/linux-5.15.93
103485 blocks; min=2, avg=10725, max=976853
took 4.084986715 seconds, 259.123255 MiB/s
dedup: 524896975
64 KiB
* ae:
/tmp/linux-5.10.167
78258 blocks; min=5, avg=12672, max=1048576
took 1.578828181 seconds, 599.059243 MiB/s
dedup: 32496698
/tmp/linux-5.15.93
82298 blocks; min=5, avg=13486, max=1048576
took 1.760683711 seconds, 601.195461 MiB/s
dedup: 473335152
* ae-32:
/tmp/linux-5.10.167
76382 blocks; min=5, avg=12984, max=1048576
took 1.460647362 seconds, 647.529061 MiB/s
dedup: 32520092
/tmp/linux-5.15.93
80328 blocks; min=5, avg=13817, max=1048576
took 1.721605414 seconds, 614.841849 MiB/s
dedup: 466254745
* buz:
/tmp/linux-5.10.167
86278 blocks; min=5, avg=11494, max=459188
took 2.255022556 seconds, 419.424459 MiB/s
dedup: 39103833
/tmp/linux-5.15.93
91335 blocks; min=5, avg=12152, max=475504
took 2.511833958 seconds, 421.411237 MiB/s
dedup: 495731311
* hashchop:
/tmp/linux-5.10.167
84267 blocks; min=1, avg=11769, max=1048576
took 2.457357053 seconds, 384.889780 MiB/s
dedup: 29580933
/tmp/linux-5.15.93
88755 blocks; min=1, avg=12505, max=1048576
took 2.718185910 seconds, 389.419668 MiB/s
dedup: 487519118
* rabin:
/tmp/linux-5.10.167
83634 blocks; min=2, avg=11858, max=1048576
took 3.502648283 seconds, 270.027573 MiB/s
dedup: 29879764
/tmp/linux-5.15.93
87809 blocks; min=2, avg=12640, max=1048576
took 3.875358160 seconds, 273.139930 MiB/s
dedup: 489198206
* rabin-mask:
/tmp/linux-5.10.167
80957 blocks; min=4, avg=12250, max=1048576
took 3.525088597 seconds, 268.308608 MiB/s
dedup: 34010282
/tmp/linux-5.15.93
85160 blocks; min=4, avg=13033, max=1048576
took 3.921338744 seconds, 269.937163 MiB/s
dedup: 481878484
* rabin-mix:
/tmp/linux-5.10.167
80450 blocks; min=3, avg=12327, max=1048576
took 3.483322314 seconds, 271.525725 MiB/s
dedup: 31594594
/tmp/linux-5.15.93
84802 blocks; min=3, avg=13088, max=1048576
took 3.956886977 seconds, 267.512078 MiB/s
dedup: 482110528
* rabin-tttd:
/tmp/linux-5.10.167
88149 blocks; min=2, avg=11250, max=1048576
took 3.671828520 seconds, 257.585998 MiB/s
dedup: 30002221
/tmp/linux-5.15.93
92588 blocks; min=2, avg=11987, max=1048576
took 4.148710861 seconds, 255.143125 MiB/s
dedup: 500599427
128 KiB
* ae:
/tmp/linux-5.10.167
75926 blocks; min=5, avg=13062, max=1048576
took 1.351032760 seconds, 700.065641 MiB/s
dedup: 28264232
/tmp/linux-5.15.93
79651 blocks; min=5, avg=13934, max=1048576
took 1.573244999 seconds, 672.822768 MiB/s
dedup: 462712070
* ae-32:
/tmp/linux-5.10.167
75503 blocks; min=5, avg=13135, max=1048576
took 1.311265326 seconds, 721.296900 MiB/s
dedup: 28264232
/tmp/linux-5.15.93
79200 blocks; min=5, avg=14014, max=1048576
took 1.545724589 seconds, 684.801848 MiB/s
dedup: 461327055
* buz:
/tmp/linux-5.10.167
80740 blocks; min=5, avg=12283, max=1048576
took 2.234070124 seconds, 423.358070 MiB/s
dedup: 35620118
/tmp/linux-5.15.93
84979 blocks; min=5, avg=13061, max=1048576
took 2.465526827 seconds, 429.326116 MiB/s
dedup: 480540916
* hashchop:
/tmp/linux-5.10.167
80267 blocks; min=5, avg=12355, max=1048576
took 2.438016184 seconds, 387.943124 MiB/s
dedup: 28189705
/tmp/linux-5.15.93
84415 blocks; min=5, avg=13148, max=1048576
took 2.700689739 seconds, 391.942488 MiB/s
dedup: 472320640
* rabin:
/tmp/linux-5.10.167
79461 blocks; min=4, avg=12481, max=1048576
took 3.508352135 seconds, 269.588564 MiB/s
dedup: 28941900
/tmp/linux-5.15.93
83288 blocks; min=4, avg=13326, max=1048576
took 3.899749214 seconds, 271.431571 MiB/s
dedup: 475210915
* rabin-mask:
/tmp/linux-5.10.167
77654 blocks; min=4, avg=12771, max=1048576
took 3.528061998 seconds, 268.082481 MiB/s
dedup: 28886270
/tmp/linux-5.15.93
81420 blocks; min=4, avg=13632, max=1048576
took 3.912836912 seconds, 270.523684 MiB/s
dedup: 470149631
* rabin-mix:
/tmp/linux-5.10.167
82181 blocks; min=3, avg=12067, max=1048576
took 3.659184797 seconds, 258.476045 MiB/s
dedup: 29035244
/tmp/linux-5.15.93
86165 blocks; min=3, avg=12881, max=1048576
took 4.122320740 seconds, 256.776491 MiB/s
dedup: 483212572
* rabin-tttd:
/tmp/linux-5.10.167
82227 blocks; min=2, avg=12061, max=1048576
took 3.747653323 seconds, 252.374362 MiB/s
dedup: 29034835
/tmp/linux-5.15.93
86194 blocks; min=2, avg=12877, max=1048576
took 4.198711991 seconds, 252.104707 MiB/s
dedup: 483232222
256 KiB
* ae:
/tmp/linux-5.10.167
75213 blocks; min=5, avg=13185, max=1048576
took 1.235175080 seconds, 765.730810 MiB/s
dedup: 27962658
/tmp/linux-5.15.93
78825 blocks; min=5, avg=14080, max=1048576
took 1.473278932 seconds, 718.475662 MiB/s
dedup: 459555163
* ae-32:
/tmp/linux-5.10.167
75152 blocks; min=5, avg=13196, max=1048576
took 1.219912292 seconds, 775.311161 MiB/s
dedup: 27962658
/tmp/linux-5.15.93
78757 blocks; min=5, avg=14093, max=1048576
took 1.451221097 seconds, 729.396133 MiB/s
dedup: 459390391
* buz:
/tmp/linux-5.10.167
77818 blocks; min=5, avg=12744, max=1048576
took 2.197690276 seconds, 430.366201 MiB/s
dedup: 32514558
/tmp/linux-5.15.93
81623 blocks; min=5, avg=13598, max=1048576
took 2.459639589 seconds, 430.353724 MiB/s
dedup: 471640091
* hashchop:
/tmp/linux-5.10.167
77841 blocks; min=5, avg=12740, max=1048576
took 2.435846935 seconds, 388.288608 MiB/s
dedup: 27769501
/tmp/linux-5.15.93
81719 blocks; min=5, avg=13582, max=1048576
took 2.697060935 seconds, 392.469833 MiB/s
dedup: 465750282
* rabin:
/tmp/linux-5.10.167
77224 blocks; min=4, avg=12842, max=1048576
took 3.455882579 seconds, 273.681641 MiB/s
dedup: 27930987
/tmp/linux-5.15.93
80883 blocks; min=4, avg=13722, max=1048576
took 3.953178089 seconds, 267.763058 MiB/s
dedup: 466444235
* rabin-mask:
/tmp/linux-5.10.167
76393 blocks; min=5, avg=12982, max=1048576
took 3.429300353 seconds, 275.803084 MiB/s
dedup: 28262897
/tmp/linux-5.15.93
80008 blocks; min=5, avg=13872, max=1048576
took 3.944018758 seconds, 268.384894 MiB/s
dedup: 464548015
* rabin-mix:
/tmp/linux-5.10.167
78799 blocks; min=5, avg=12585, max=1048576
took 3.666534806 seconds, 257.957899 MiB/s
dedup: 28326427
/tmp/linux-5.15.93
82569 blocks; min=5, avg=13442, max=1048576
took 4.104135454 seconds, 257.914259 MiB/s
dedup: 471972159
* rabin-tttd:
/tmp/linux-5.10.167
78842 blocks; min=4, avg=12579, max=1048576
took 3.743866536 seconds, 252.629629 MiB/s
dedup: 28326023
/tmp/linux-5.15.93
82593 blocks; min=4, avg=13438, max=1048576
took 4.209662057 seconds, 251.448938 MiB/s
dedup: 471996748
512 KiB
* ae:
/tmp/linux-5.10.167
75013 blocks; min=5, avg=13221, max=1048576
took 1.195962831 seconds, 790.836965 MiB/s
dedup: 27698692
/tmp/linux-5.15.93
78546 blocks; min=5, avg=14130, max=1048576
took 1.425389477 seconds, 742.614614 MiB/s
dedup: 458715030
* ae-32:
/tmp/linux-5.10.167
75009 blocks; min=5, avg=13221, max=1048576
took 1.171846616 seconds, 807.112127 MiB/s
dedup: 27698692
/tmp/linux-5.15.93
78540 blocks; min=5, avg=14132, max=1048576
took 1.397276252 seconds, 757.556034 MiB/s
dedup: 458715030
* buz:
/tmp/linux-5.10.167
76362 blocks; min=5, avg=12987, max=1048576
took 2.123368396 seconds, 445.429826 MiB/s
dedup: 29505771
/tmp/linux-5.15.93
80022 blocks; min=5, avg=13870, max=1048576
took 2.444391751 seconds, 433.038221 MiB/s
dedup: 464532973
* hashchop:
/tmp/linux-5.10.167
76464 blocks; min=5, avg=12970, max=1048576
took 2.373214659 seconds, 398.536058 MiB/s
dedup: 27724748
/tmp/linux-5.15.93
80143 blocks; min=5, avg=13849, max=1048576
took 2.721677547 seconds, 388.920082 MiB/s
dedup: 462395440
* rabin:
/tmp/linux-5.10.167
76290 blocks; min=5, avg=12999, max=1048576
took 3.479927777 seconds, 271.790588 MiB/s
dedup: 27919270
/tmp/linux-5.15.93
79877 blocks; min=5, avg=13895, max=1048576
took 3.953208484 seconds, 267.761000 MiB/s
dedup: 462973776
* rabin-mask:
/tmp/linux-5.10.167
75805 blocks; min=5, avg=13082, max=1048576
took 3.423279027 seconds, 276.288204 MiB/s
dedup: 27703202
/tmp/linux-5.15.93
79375 blocks; min=5, avg=13983, max=1048576
took 3.935454988 seconds, 268.968914 MiB/s
dedup: 462142168
* rabin-mix:
/tmp/linux-5.10.167
77073 blocks; min=5, avg=12867, max=1048576
took 3.515042323 seconds, 269.075456 MiB/s
dedup: 27919707
/tmp/linux-5.15.93
80736 blocks; min=5, avg=13747, max=1048576
took 4.040185707 seconds, 261.996634 MiB/s
dedup: 466041699
* rabin-tttd:
/tmp/linux-5.10.167
77118 blocks; min=4, avg=12860, max=1048576
took 3.604599129 seconds, 262.390236 MiB/s
dedup: 27919305
/tmp/linux-5.15.93
80763 blocks; min=4, avg=13743, max=1048576
took 4.174552265 seconds, 253.563733 MiB/s
dedup: 466058912
1024 KiB
* ae:
/tmp/linux-5.10.167
74908 blocks; min=5, avg=13239, max=2097152
took 1.148221358 seconds, 823.718883 MiB/s
dedup: 27698692
/tmp/linux-5.15.93
78394 blocks; min=5, avg=14158, max=2097152
took 1.382393525 seconds, 765.711815 MiB/s
dedup: 458803804
* ae-32:
/tmp/linux-5.10.167
74908 blocks; min=5, avg=13239, max=2097152
took 1.145963396 seconds, 825.341907 MiB/s
dedup: 27698692
/tmp/linux-5.15.93
78394 blocks; min=5, avg=14158, max=2097152
took 1.360025052 seconds, 778.305557 MiB/s
dedup: 458803804
* buz:
/tmp/linux-5.10.167
75575 blocks; min=5, avg=13122, max=2097152
took 2.116215122 seconds, 446.935477 MiB/s
dedup: 28602260
/tmp/linux-5.15.93
79119 blocks; min=5, avg=14028, max=2097152
took 2.446465878 seconds, 432.671089 MiB/s
dedup: 461247659
* hashchop:
/tmp/linux-5.10.167
75652 blocks; min=5, avg=13109, max=2097152
took 2.370107428 seconds, 399.058542 MiB/s
dedup: 27703365
/tmp/linux-5.15.93
79247 blocks; min=5, avg=14006, max=2097152
took 2.697181397 seconds, 392.452305 MiB/s
dedup: 460345252
* rabin:
/tmp/linux-5.10.167
75715 blocks; min=5, avg=13098, max=2097152
took 3.477917767 seconds, 271.947665 MiB/s
dedup: 27703202
/tmp/linux-5.15.93
79241 blocks; min=5, avg=14007, max=2097152
took 3.961286973 seconds, 267.214939 MiB/s
dedup: 460992114
* rabin-mask:
/tmp/linux-5.10.167
75464 blocks; min=5, avg=13142, max=2097152
took 3.485350020 seconds, 271.367756 MiB/s
dedup: 27698692
/tmp/linux-5.15.93
78980 blocks; min=5, avg=14053, max=2097152
took 3.957530892 seconds, 267.468552 MiB/s
dedup: 460028687
* rabin-mix:
/tmp/linux-5.10.167
76115 blocks; min=5, avg=13029, max=2097152
took 3.499696731 seconds, 270.255307 MiB/s
dedup: 27706192
/tmp/linux-5.15.93
79681 blocks; min=5, avg=13929, max=2097152
took 3.978703999 seconds, 266.045189 MiB/s
dedup: 462551956
* rabin-tttd:
/tmp/linux-5.10.167
76157 blocks; min=5, avg=13022, max=2097152
took 3.572019241 seconds, 264.783460 MiB/s
dedup: 27705791
/tmp/linux-5.15.93
79704 blocks; min=5, avg=13925, max=2097152
took 4.055896841 seconds, 260.981750 MiB/s
dedup: 462547696
Where's the source code ?
If you're curious about this and/or would like to ran those tests yourself/on your own hardware : it's all available on a nice little git repository. :)
The code can be browsed right here online, or you can just close
the repo : git clone git://lila.oss/test-rolling.git
And as a convenience, here's a tarball if you don't wanna use git.